Vision UFormer: Long-Range Monocular Absolute Depth Estimation

ABSTRACT
We introduce Vision UFormer (ViUT), a novel deep neural long-range monocular depth estimator. The input is an RGB image, and the output is an image that stores the absolute distance of the object in the scene as its per-pixel values. ViUT consists of a Transformer encoder and a ResNet decoder combined with the UNet style of skip connections. It is trained on 1M images across ten datasets in a staged regime that starts with easier-to-predict data such as indoor photographs and continues to more complex long-range outdoor scenes. We show that ViUT provides comparable results for normalized relative distances and short-range classical datasets such as NYUv2 and KITTI. We further show that it successfully estimates absolute long-range depth in meters. We validate ViUT on a wide variety of long-range scenes showing its high estimation capabilities with a relative improvement of up to 23%. Absolute depth estimation finds application in many areas, and we show its usability in image composition, range annotation, defocus, and scene reconstruction.
OVERVIEW
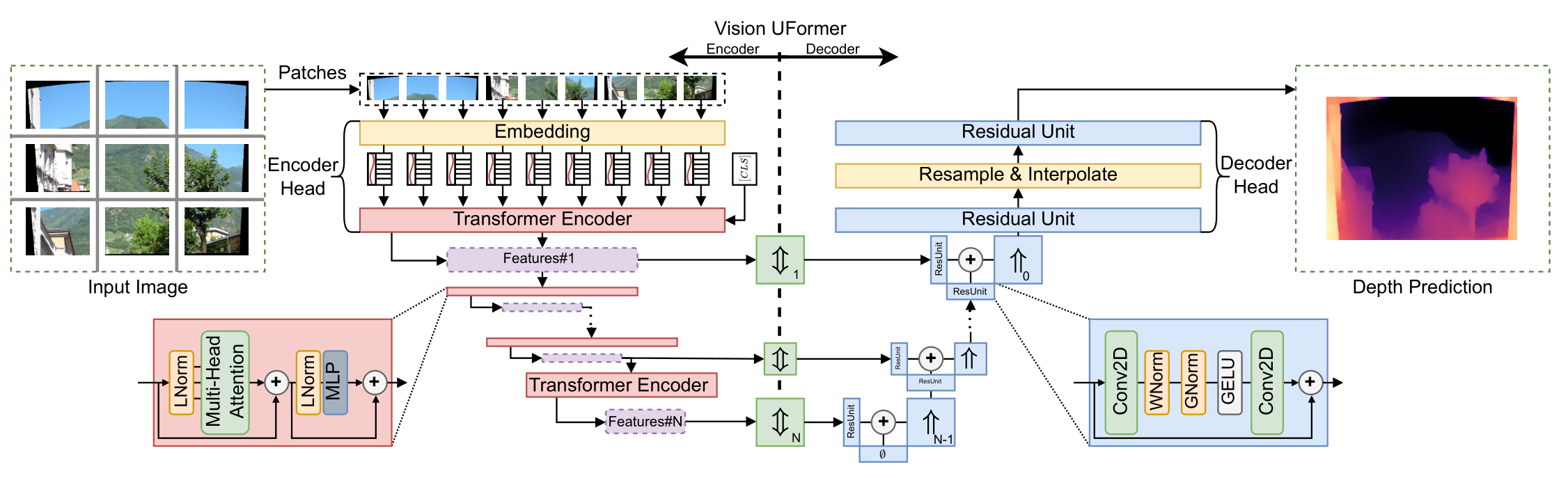
The Vision UFormer (ViUT) consists of a Vision Transformer encoder (left) and ResNet decoder (right) in a UNet configuration. The input image is split into embedded patches and passed through a sequence of multi-head self-attention layers. Multi-scale feature vectors are extracted from individual tiers of the encoder and processed into 2D feature maps by the up-down-rescale operation (⇕). The decoder aggregates these maps, upscaling them (⇑) with bilinear interpolation into the final depth prediction.
ADDITIONAL MATERIALS
CITATION
@article{polasek23viut,
title = {{Vision UFormer}: Long-Range Monocular Absolute Depth Estimation},
journal = {Computers \& Graphics},
volume = {111},
pages = {180-189},
year = {2023},
issn = {0097-8493},
doi = {https://doi.org/10.1016/j.cag.2023.02.003},
url = {https://www.sciencedirect.com/science/article/pii/S0097849323000262},
author = {Polasek, Tomas and \v{C}ad\'{\i}k, Martin and Keller, Yosi and Benes, Bedrich},
}
APPLICATIONS

We show several applications of the depths produced by the ViUT model. (a) and (e) shows direct use of depth in annotation or range-finding. We apply a depth-dependant Gaussian filter in (b) for depth of field synthesis. In (c) and (h), we show metric object insertion by placing three identical copies of a human character of approximately 1.8m in height into the scene. Thanks to the absolute depth, we observe the size of the character diminishing the further it is placed. In (f) and (g) we show object removal by using the depth map as a mask for image synthesis. Lastly, (d) shows a full 3D scene reconstruction with correct absolute scaling.


