CrossLocate:
Cross-modal Large-scale Visual Geo-Localization in Natural Environments using Rendered Modalities
|
Jan Tomešek, itomesek@fit.vutbr.cz Martin Čadík, cadik@fit.vutbr.cz Jan Brejcha, ibrejcha@fit.vutbr.cz |
Abstract
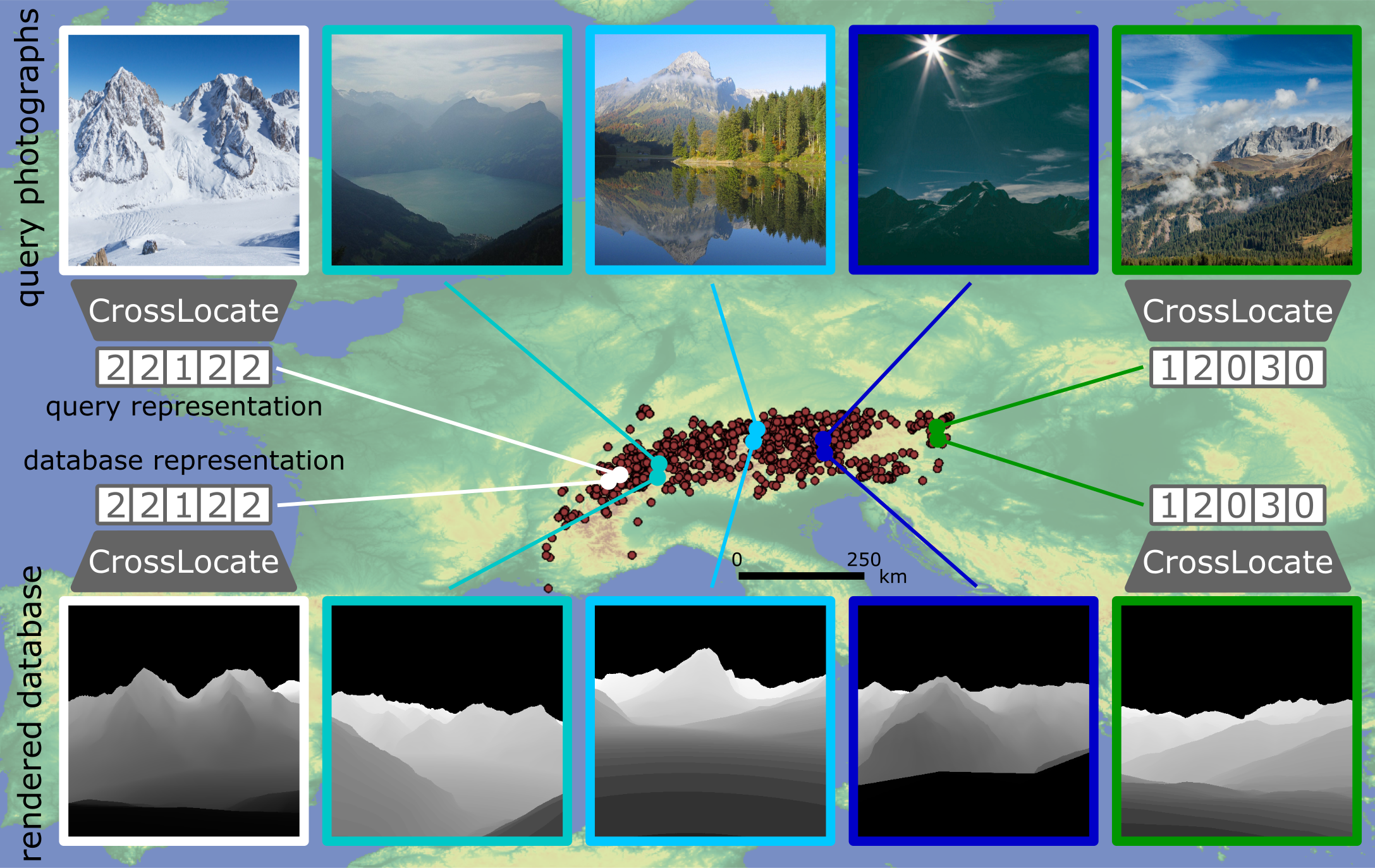
We propose a novel approach to visual geo-localization in natural environments. This is a challenging problem due to vast localization areas, the variable appearance of outdoor environments and the scarcity of available data. In order to make the research of new approaches possible, we first create two databases containing ''synthetic'' images of various modalities. These image modalities are rendered from a 3D terrain model and include semantic segmentations, silhouette maps and depth maps. By combining the rendered database views with existing datasets of photographs (used as ''queries'' to be localized), we create a unique benchmark for visual geo-localization in natural environments, which contains correspondences between query photographs and rendered database imagery. The distinct ability to match photographs to synthetically rendered databases defines our task as ''cross-modal''. On top of this benchmark, we provide thorough ablation studies analysing the localization potential of the database image modalities. We reveal the depth information as the best choice for outdoor localization. Finally, based on our observations, we carefully develop a fully-automatic method for large-scale cross-modal localization using image retrieval. We demonstrate its localization performance outdoors in the entire state of Switzerland. Our method reveals a large gap between operating within a single image domain (e.g. photographs) and working across domains (e.g. photographs matched to rendered images), as gained knowledge is not transferable between the two. Moreover, we show that modern localization methods fail when applied to such a cross-modal task and that our method achieves significantly better results than state-of-the-art approaches. The datasets, code and trained models are available on this website.
Additional Materials
- Paper (pdf) [5.4 MB]
- Supplementary Material (pdf) [3.4 MB]
- Poster (pdf) [11.4 MB]
- Code (available on GitHub)
- Dataset (available for browsing)
Whenever you use the dataset, please acknowledge it by citing our paper.